


Cómo entrenar IA: guía completa y actualizada para 2025
Ùltima actualización en 17 junio 2025 a las 11:20 am
 5,00/5
5,00/5Los fundamentos del entrenamiento de una inteligencia artificial
¿Qué es el entrenamiento de una IA?
El entrenamiento de una inteligencia artificial es un proceso que permite a un sistema informático aprender a analizar datos y realizar ciertas tareas con precisión. Al igual que un cerebro humano que se perfecciona gracias a la experiencia, una IA asimila información para crear modelos de predicción y adaptarse a diferentes situaciones. El entrenamiento de un programa de IA se basa entonces en la exposición del software a vastos conjuntos de datos que le permitirán afinar progresivamente sus respuestas.
Al entrenar una IA, una empresa y una agencia de IA puede optimizar su proceso de producción y ayudar a sus colaboradores a tomar mejores decisiones. De hecho, una inteligencia artificial bien formada constituye un verdadero aliado en la productividad, en la reducción de los costes operativos y en la innovación tecnológica. Una solución de IA bien entrenada es entonces primordial para permitir a una empresa mantenerse competitiva y adaptarse a los cambios en el mundo real.
Puntos clave del artículo
- ¿Qué es el entrenamiento de IA?: El entrenamiento de IA implica exponer un sistema de aprendizaje a grandes conjuntos de datos para permitirle analizar, predecir y adaptarse a diferentes situaciones, ya sea en los negocios o en la vida cotidiana.
- Los pasos clave para entrenar una IA: recopilación y preparación de datos, elección del algoritmo y modelo, fase de entrenamiento y optimización, evaluación y validación del modelo.
- Los diferentes enfoques para entrenar una IA: aprendizaje supervisado, aprendizaje no supervisado, aprendizaje por refuerzo.
- Las herramientas utilizadas para entrenar una IA: frameworks (TensorFlow, PyTorch, Scikit-learn), recursos computacionales (CPU, GPU, TPU), bases de datos y almacenamiento (HDD, SDD, SAN, NAS).
- Modelos de IA entrenados más comúnmente : GPT, CNN, RNN.
- Soluciones para optimizar un modelo de IA: ajuste fino y aprendizaje por transferencia, ajuste de hiperparámetros, estrategia de mejora continua.
- Soluciones futuras en el aprendizaje de IA: AutoML, IA de código abierto, transformadores autorregresivos.
Aprendizaje supervisado vs. Aprendizaje no supervisado vs. aprendizaje por refuerzo
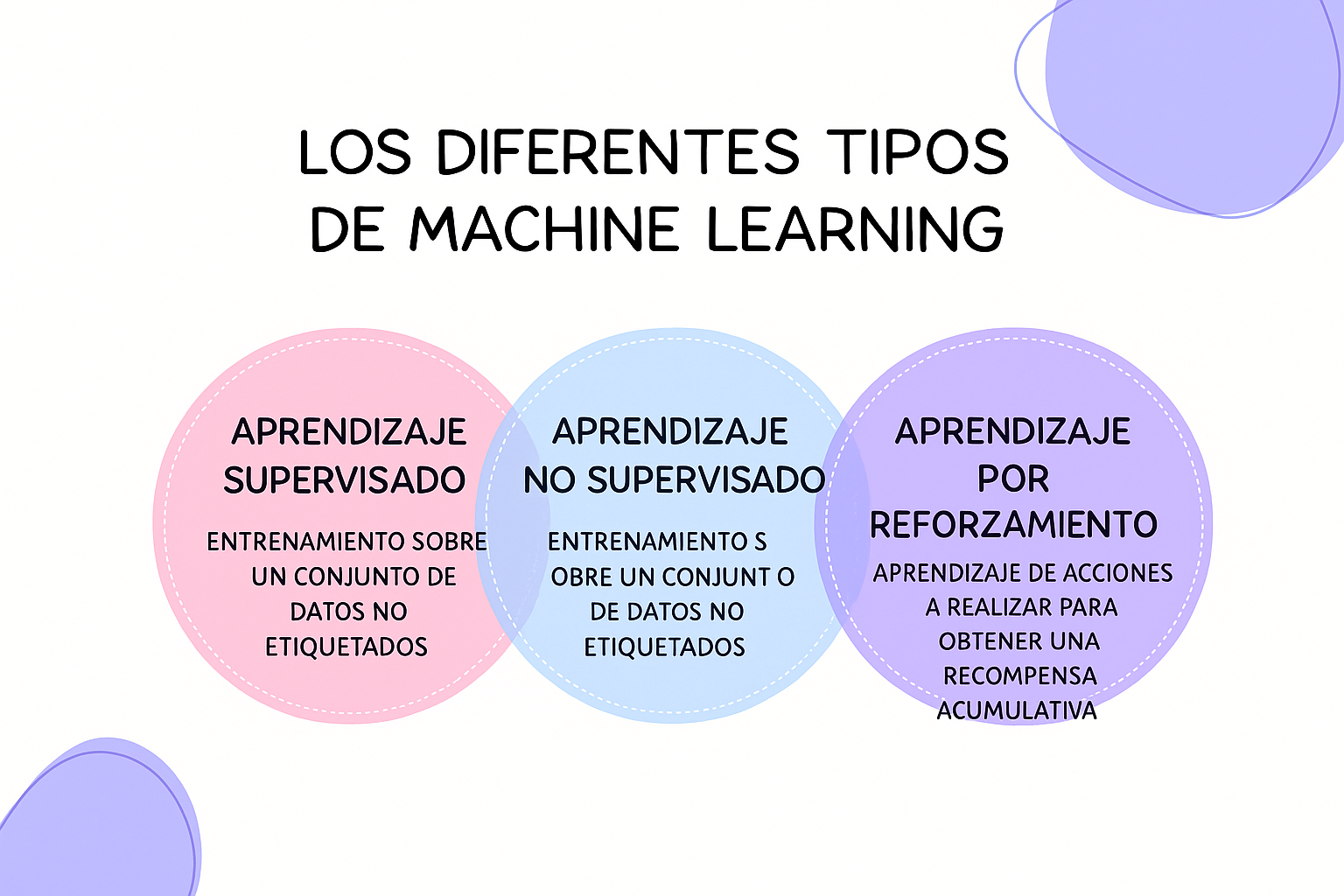
Los modelos de inteligencia artificial se basan en tres enfoques principales de entrenamiento: el aprendizaje supervisado, el aprendizaje no supervisado y el aprendizaje por refuerzo. El aprendizaje supervisado utiliza datos etiquetados para enseñar a la IA a asociar entradas y salidas de datos. El algoritmo se basa entonces en varios ejemplos de predicciones para generar nuevos datos.
Por el contrario, el aprendizaje no supervisado funciona sin datos etiquetados. La IA explora libremente la información, detecta estructuras ocultas y agrupa la información recibida según similitudes. Este modo de aprendizaje es ideal para el análisis de datos complejos que no requiere supervisión humana.
El aprendizaje por refuerzo, por su parte, se basa en un sistema de recompensas y penalizaciones. El algoritmo aprende por ensayo y error, ajustando progresivamente sus decisiones a medida que recibe respuestas para mejorar la calidad de las predicciones. Una agencia de IA en Madrid puede entonces adoptar este enfoque para adaptarse a entornos dinámicos y optimizar su rendimiento de forma autónoma.
Los modelos de IA más comúnmente entrenados (GPT, CNN, RNN, etc.)
Según sus necesidades y en función del tipo de datos a procesar, las empresas pueden orientarse hacia el entrenamiento de un modelo de inteligencia artificial específico. Sin embargo, algunos modelos destacan y son comúnmente utilizados por los profesionales del sector como una agencia de IA de marketing.
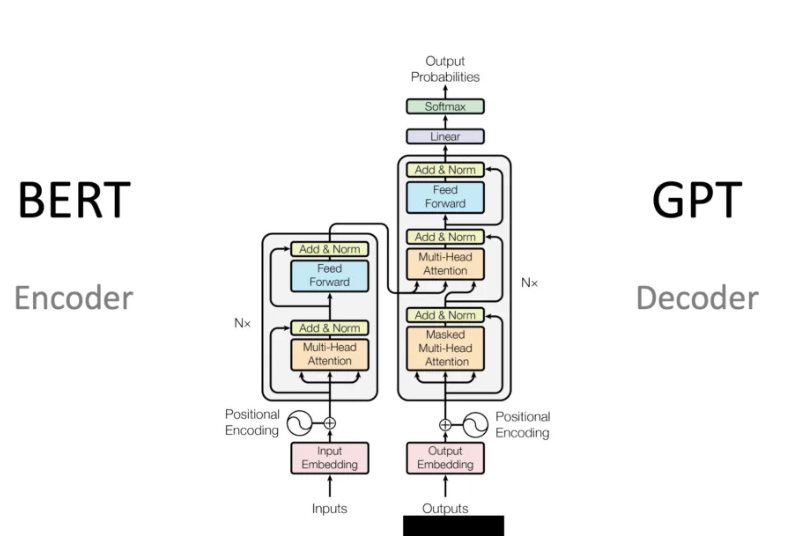
Entre los más utilizados, encontrarás el modelo GPT que se basa en la arquitectura Transformer, especializado en el procesamiento del lenguaje natural. Este modelo aprende gracias a un entrenamiento con enormes volúmenes de textos, permitiéndole generar respuestas relevantes y contextuales. El CNN, por su parte, está diseñado para el análisis de imágenes. Gracias a varias capas de convolución, identifica patrones visuales como formas y texturas de objetos. Este modelo se ha vuelto esencial en el reconocimiento facial y en la visión por computadora. El RNN, a su vez, se distingue por su capacidad para procesar datos secuenciales. Sus conexiones recurrentes le permiten memorizar información a lo largo de varias etapas, facilitando el reconocimiento de voz y el análisis de series temporales.
Los recientes avances en inteligencia artificial han permitido el desarrollo de modelos más potentes, adaptados a tareas específicas:
- BERT mejora la comprensión del lenguaje analizando el contexto de las palabras en una frase, lo que lo hace eficaz para la búsqueda de información.
- Las GAN (Redes Generativas Adversarias): que generan imágenes y vídeos ultra realistas, enfrentando dos redes neuronales.
- LSTM: es una variante de las RNN, que gestiona las dependencias a largo plazo en datos secuenciales, útil en reconocimiento de voz y predicción de series temporales.
- Los autoencoders: que reducen la dimensionalidad de los datos y detectan anomalías comprimiendo y reconstruyendo las líneas de código.
- Las Deep Q-Networks: utilizadas para desarrollar sistemas autónomos, especialmente en robótica y videojuegos.
Fuente: blog-nouvelles-technologies.fr
4 Pasos clave para entrenar una IA
1. Recopilación y preparación de datos
La eficacia de una IA se basa esencialmente en la calidad y relevancia de los datos que se ponen a su disposición. Durante la recopilación de información, asegúrese de recoger datos variados, representativos y adaptados a sus objetivos. De hecho, cuanta más información diversa y fiable tenga, más podrá mejorar la precisión de las predicciones. Seleccione fuentes relevantes y elimine los posibles sesgos desde el principio de su investigación. Esto le permitirá obtener un conjunto de datos robusto, ideal para el aprendizaje de su solución de inteligencia artificial.
A continuación, limpie y prepare cuidadosamente la información recibida. Por ejemplo, puede dividir sus datos en varios conjuntos para facilitar el aprendizaje de su modelo de IA. También puede etiquetar los datos para que la lectura sea lo más automática posible. Gracias a una primera fase de preparación, obtendrá así un sistema de inteligencia artificial capaz de reconocer fácilmente patrones y ofrecer resultados precisos.
La recopilación y preparación de datos es una tarea compleja, especialmente cuando se trata de una compilación de múltiples fuentes. Para tener éxito en este proceso, puede solicitar la intervención de una agencia especializada en Deep Learning. Este profesional le ayudará a explotar correctamente sus datos y le asistirá en la creación de una solución eficaz para optimizar el rendimiento de su IA.
2. Elección del algoritmo y del modelo
La elección de tu algoritmo y modelo de aprendizaje influye directamente en la capacidad del sistema para aprender y ejecutar tareas específicas. En función de tus datos de entrenamiento, tienes la opción de elegir entre varios modelos: una red neuronal, una máquina de vectores de soporte, un árbol de decisión, etc.
Durante tu selección, opta por un modelo que responda perfectamente a tus objetivos. Las redes neuronales (RNN), por ejemplo, son más hábiles en el procesamiento de enormes cantidades de datos, mientras que los modelos basados en Deep Learning son más eficaces en el análisis predictivo y en el reconocimiento de imágenes. Otros factores (dimensión del proyecto, disponibilidad de recursos informáticos) también son parámetros a tener en cuenta a la hora de elegir tu modelo de aprendizaje inteligente.
3. Fase de entrenamiento y optimización
Esta etapa de entrenamiento se basa en un proceso iterativo destinado a mejorar el rendimiento de tu modelo de inteligencia artificial. Una vez que hayas seleccionado tu algoritmo, introduce tus datos de entrenamiento en tu modelo y establece los parámetros que guiarán al algoritmo en su formación: tamaño del lote, tasa de aprendizaje, tasa de éxito, número de épocas… El algoritmo ajustará entonces progresivamente sus diferentes parámetros para minimizar los errores en sus respuestas.
También puedes optar por externalizar los entrenamientos en un dispositivo de IA en la nube para dar a tu algoritmo el tiempo necesario para integrar tus datos sin ralentizar el buen funcionamiento de los diferentes procesos. Para saber si tu modelo de aprendizaje está aprendiendo y funcionando correctamente, observa atentamente los indicadores de rendimiento como la precisión de las respuestas o las posibles pérdidas durante el entrenamiento.
A continuación, realiza ajustes e iteraciones adicionales si las primeras predicciones de tu modelo de IA no son satisfactorias. En el caso del entrenamiento de un chatbot, por ejemplo, una agencia web puede optimizar su modelo de lenguaje utilizando técnicas de Fine-tuning.
4. Evaluación y validación del modelo
Para facilitar su evaluación, pruebe su modelo de aprendizaje en diferentes escenarios y analice las respuestas utilizando pruebas unitarias, pruebas A/B o mediante pruebas de usuario. Estos métodos le permitirán medir la precisión y eficacia del sistema frente a diferentes tareas. Al mismo tiempo, verifique la veracidad de las respuestas e interacciones, y calcule el tiempo de respuesta para cada consulta.
A continuación, establezca un proceso de recopilación para permitir que su modelo de inteligencia artificial mejore su rendimiento. Tenga en cuenta las opiniones de los usuarios a través de formularios, encuestas o realice entrevistas directas.
Y como los datos y las necesidades de los usuarios están en constante evolución, no olvide medir frecuentemente su solución de inteligencia artificial. Establezca un equipo humano dedicado a monitorear su modelo de aprendizaje. Si su solución de IA debe integrarse en una plataforma de comercio electrónico, no dude en recurrir a una agencia de diseño de sitios web para validar su modelo de aprendizaje. Este profesional le ayudará a crear una interfaz de usuario ideal para probar e interactuar con el modelo.
Fuente: larevueia.fr
Tipos de entrenamiento y sus aplicaciones
Aprendizaje supervisado: casos de uso y limitaciones
El aprendizaje supervisado se basa en el uso de datos etiquetados para entrenar un modelo de aprendizaje. Gracias a este enfoque, el modelo aprende progresivamente a generalizar y a realizar análisis predictivos precisos sobre nuevos datos.
De hecho, el aprendizaje supervisado se utiliza en el desarrollo de aplicaciones como la detección de fotos, el reconocimiento de voz y la predicción de tendencias de mercado. La principal ventaja de este modelo de entrenamiento reside en su precisión y fiabilidad. Sin embargo, el uso del aprendizaje supervisado requiere un volumen importante de datos etiquetados, lo que hace que su implementación sea más costosa.
Aprendizaje no supervisado: oportunidades y desafíos
El aprendizaje no supervisado es un modelo de entrenamiento que permite a los algoritmos analizar datos no etiquetados e identificar estructuras sin intervención externa. Este enfoque se basa entonces en técnicas como el clustering, que permite agrupar datos similares, o la reducción de dimensionalidad, que simplifica la representación de los datos.
El aprendizaje no supervisado es particularmente útil en la exploración de bases de datos masivas y la detección de fraudes. Sin embargo, los resultados derivados del aprendizaje no supervisado pueden volverse complejos y difíciles de validar. Además, la ausencia de datos etiquetados hace que la evaluación de este tipo de modelo sea más incierta.
Aprendizaje por refuerzo: ¿cuándo y por qué utilizarlo?
El aprendizaje por refuerzo permite a los modelos de IA interactuar mejor con su entorno. El algoritmo toma decisiones en función de su estado actual y recibe una recompensa por cada acción exitosa, mejorando la eficacia del modelo con el tiempo.
Este tipo de aprendizaje es particularmente eficaz en áreas que requieren una excelente adaptación. El aprendizaje por refuerzo permite crear secuencias de acciones optimizadas y facilita la creación de entornos dinámicos como en el campo de la robótica o en el universo de los videojuegos. Sin embargo, este tipo de aprendizaje requiere un gran número de interacciones para evitar comportamientos no deseados.
Herramientas y tecnologías utilizadas
Frameworks populares (TensorFlow, PyTorch, Scikit-learn)
TensorFlow se encuentra entre las referencias en materia de entrenamiento de soluciones de inteligencia artificial y Deep Learning. Gracias a sus numerosas funcionalidades, esta herramienta permite crear modelos de aprendizaje a gran escala y ayuda a explorar diversos enfoques para utilizar la inteligencia artificial de manera eficaz. TensorFlow es especialmente útil en la clasificación de números, el reconocimiento de imágenes y el análisis de textos. Este framework incluso facilita la creación de aplicaciones con Python y acelera la creación de gráficos de datos o Dataflow.
En cuanto a PyTorch, este framework de código abierto ofrece un enfoque dinámico durante el entrenamiento de una inteligencia artificial. Muy utilizado en el campo de la ciencia de datos y en el Deep Learning, esta herramienta facilita la creación de modelos de IA complejos gracias a un enfoque flexible y modular. Este framework también admite una multitud de parámetros para facilitar el entrenamiento de algoritmos de IA.
Scikit-Learn es una biblioteca de Python diseñada para simplificar el desarrollo de modelos de machine learning. Su interfaz intuitiva permite acceder fácilmente a una amplia gama de algoritmos. Admite tareas de regresión, clustering y reducción de dimensionalidad, facilitando el análisis y la explotación de datos. Booking.com, por ejemplo, utiliza este framework para crear una IA generativa y recomendar destinos únicos a sus clientes.
Recursos de cálculo: CPU vs GPU vs TPU
La potencia de estos recursos de cálculo como las GPU, las CPU y las TPU te permitirá procesar operaciones complejas y mejorará la velocidad de respuesta de los modelos de IA. Las CPU (Central Processing Unit o Unidad Central de Procesamiento) o los procesadores de propósito general realizan tareas secuenciales y aceleran el preprocesamiento de datos. Sin embargo, la potencia de las CPU sigue siendo limitada para el entrenamiento de modelos en Deep Learning.
En cuanto a las unidades de cálculo GPU (Graphics Processing Unit o Unidad de Procesamiento Gráfico), destacan en el procesamiento simultáneo de grandes conjuntos de datos. Inicialmente diseñadas para el renderizado gráfico, este tipo de arquitectura acelera el entrenamiento de modelos, especialmente en el marco de las operaciones de visión por ordenador y en el procesamiento del lenguaje natural.
Las TPU o Tensor Processing Unit (Unidad de Procesamiento Tensorial), por su parte, son procesadores especializados en la optimización de cálculos matriciales, indispensables en el Machine Learning. Este tipo de recurso ofrece un alto rendimiento y permite entrenar varios modelos de aprendizaje. Además, su bajo consumo energético lo hace ideal para el entrenamiento de IA a gran escala.
Bases de datos y almacenamiento de datos
Las bases de datos y las soluciones de almacenamiento mejoran la velocidad de procesamiento de tus datos y garantizan una gestión eficaz de tu información. A la hora de elegir tu herramienta de almacenamiento, debes considerar ciertos aspectos como la escalabilidad, la seguridad y el rendimiento de tu dispositivo de almacenamiento.
Tienes varias opciones para asegurar tus conjuntos de datos. Puedes optar por soluciones en la nube que ofrecen tanto flexibilidad como escalabilidad, o dirigirte hacia sistemas de almacenamiento especializados que te garantizarán un rendimiento optimizado. Entre las soluciones clásicas, encontrarás el almacenamiento en discos duros HDD y SSD. Sin embargo, si el entrenamiento de tu modelo de IA requiere un enorme volumen de datos, opta por infraestructuras SAN y NAS que ofrecen mayor capacidad de almacenamiento en redes dedicadas.
Otras alternativas también pueden facilitar el almacenamiento de datos de entrenamiento. Los profesionales pueden orientarse hacia soluciones escalables como los discos SSD NVMe, la memoria persistente o incluso la memoria SCM. Para evitar latencias y responder a las necesidades de ancho de banda de la empresa, puedes optar por dispositivos de almacenamiento de IA descentralizados alimentados por la computación Edge. Esta tecnología te permitirá explotar todo el potencial de tu solución de IA en numerosos sitios durante el despliegue.
Problemas y desafíos en el entrenamiento de una IA
Sobreajuste y subajuste
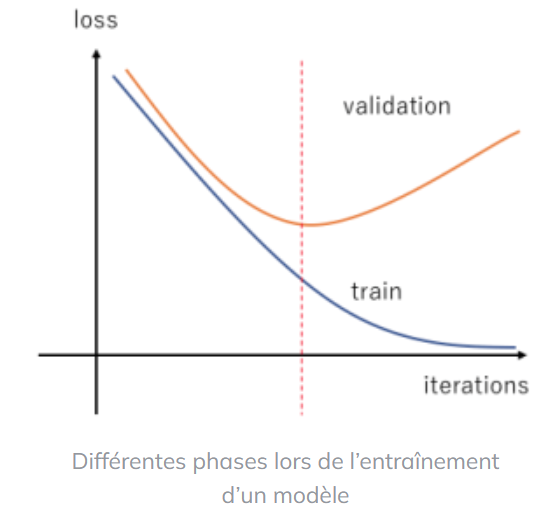
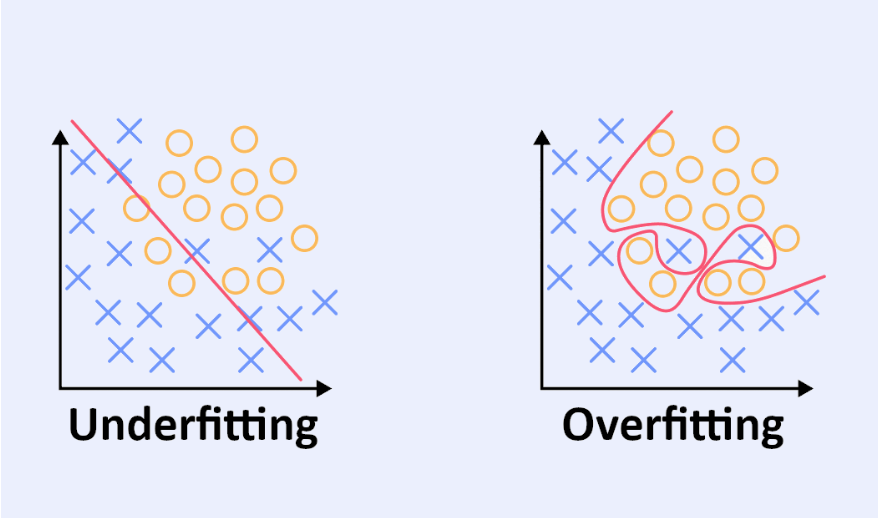
A pesar de su capacidad de adaptación, los algoritmos de aprendizaje automático no están exentos de errores. El overfitting y el underfitting, por ejemplo, crean modelos ineficaces que comprometen la fiabilidad de los análisis predictivos. El overfitting o sobreajuste provoca una especialización excesiva del modelo en los datos de entrenamiento, reduciendo así su capacidad para generalizar la información. El underfitting, por el contrario, demuestra la incapacidad del algoritmo para aprender correctamente las tendencias a partir de los datos de entrenamiento (Training Set).
Para mitigar los problemas de overfitting y underfitting, aumente el tamaño, la diversidad y la calidad de sus conjuntos de datos. Durante las pruebas, asegúrese de que los datos de entrada se han utilizado tanto para el aprendizaje como para las diferentes pruebas. Utilice en particular la técnica de validación cruzada (cross-validation) para evaluar la capacidad de generalización de su modelo.
Para registrar los procesos de desarrollo de sus modelos, puede orientarse hacia herramientas de seguimiento de experimentos y operaciones de aprendizaje automático como TensorBoard, MLflow o Azure ML Studio. Estos dispositivos le servirán para hacer un seguimiento de las métricas, los hiperparámetros y los datos esenciales para el entrenamiento de su IA.
Sesgo de datos y ética de la IA
Cuando los datos utilizados no son lo suficientemente representativos o contienen preferencias implícitas, el algoritmo de IA puede generar resultados erróneos o sesgados. Algunos errores pueden entonces provocar fallos durante el entrenamiento de un modelo de IA. Este es particularmente el caso de los sesgos de selección y los sesgos implícitos que hacen que las respuestas sean poco fiables y comprometen la precisión de un modelo de entrenamiento.
Para reducir el impacto de estos sesgos y garantizar predicciones justas, adopte un enfoque proactivo realizando auditorías regulares y actualizando sus datos de entrenamiento. Utilice también conjuntos de datos con ejemplos variados y equilibrados para asegurar una representatividad óptima durante la predicción. Y para evaluar el rendimiento de los algoritmos, realice pruebas A/B utilizando datos reales de su empresa. Esta técnica no solo enriquece su modelo de inteligencia artificial, sino que también promueve un uso ético e inclusivo de su solución de IA.
Costo y rendimiento del entrenamiento
El costo del entrenamiento de un modelo de inteligencia artificial representa un desafío importante, especialmente para las pequeñas empresas. El etiquetado de datos, por ejemplo, sigue siendo una operación que consume mucho tiempo y genera gastos adicionales. La instalación de clústeres de cálculo y sistemas de almacenamiento en la nube, por su parte, conlleva altos costos de mantenimiento, sin olvidar los gastos en términos de formación del personal.
Para reducir estos gastos, comience con proyectos piloto para tener una idea del costo inicial de despliegue de su modelo. Para obtener una solución más accesible y mantener un alto nivel de rendimiento, opte por técnicas innovadoras como la «destilación de conocimientos» o la «esparsificación» que le permitirán comprimir sus modelos de entrenamiento. También puede dirigirse a servicios en la nube como AWS, Azure o Google Cloud para disminuir su inversión inicial en términos de infraestructura.
Optimización y mejora del modelo
Ajuste fino y transferencia de aprendizaje
Para mejorar la relevancia de los algoritmos, las empresas pueden utilizar varias técnicas. El ajuste fino, por ejemplo, permite optimizar un modelo preentrenado adaptándolo a un dominio específico. Al habituar la IA a un conjunto de datos dirigido, las empresas pueden reducir significativamente los errores de predicción y afinar la precisión del modelo. De hecho, estas técnicas son particularmente eficaces en ámbitos de actividad muy concretos: generación de líneas de código, atención al cliente, clasificación de documentos, imágenes médicas, etc.
La transferencia de aprendizaje, por su parte, permite realizar una nueva tarea basándose en predicciones anteriores. Este método de optimización reduce considerablemente las necesidades empresariales de datos y potencia de cálculo. La transferencia de aprendizaje incluso evita reiniciar el modelo de aprendizaje. Los modelos preentrenados como GPT, BERT o XLNet, por ejemplo, utilizan la transferencia de aprendizaje para entrenar su modelo en la representación de palabras y frases.
Ajuste de Hiperparámetros (Búsqueda en Cuadrícula, Optimización Bayesiana)
El ajuste de hiperparámetros o Hyperparameter Tuning mejora la precisión de las predicciones ajustando los parámetros de aprendizaje. Esto puede referirse a las variables de entrenamiento que pueden crear problemas de sobreajuste y subajuste: forma, tamaño y conexiones entre una red neuronal, tolerancia a errores, velocidad de aprendizaje, etc.
Varias técnicas te permiten entonces proceder al ajuste de tus hiperparámetros:
- La búsqueda en cuadrícula o Grid Search: que permite probar y combinar varios valores de diferentes parámetros con el objetivo de encontrar el mejor ajuste posible;
- La búsqueda aleatoria: que selecciona los hiperparámetros de forma no estructurada. Este método es más eficaz cuando las métricas de entrenamiento son más bajas.
- La optimización bayesiana: que modela el rendimiento de los parámetros utilizando un modelo de probabilidad. La Optimización Bayesiana facilita una mejor exploración de los datos de entrenamiento gracias a una selección iterativa de hiperparámetros.
Estrategias de mejora continua
Actualmente, los modelos de inteligencia artificial deben demostrar una gran flexibilidad para mantenerse competitivos. Para adaptar su modelo de IA a nuevos datos y afinar su rendimiento, opte por estrategias de mejora continua que actualizarán los algoritmos de IA. Además, este tipo de enfoque mejora la robustez de su modelo gracias a la retroalimentación de los usuarios.
Para implementar con éxito su enfoque de mejora continua, comience por definir objetivos claros utilizando el método SMART. A continuación, identifique las debilidades de su sistema de aprendizaje y los diferentes procesos de entrenamiento que necesitan mejoras con el análisis DAFO (Debilidades, Amenazas, Fortalezas, Oportunidades). Después de cada optimización, evalúe también los resultados obtenidos utilizando cuadros de mando y refiriéndose a sus indicadores clave de rendimiento (KPIs).
En cada etapa del entrenamiento de su modelo de IA, no dude en involucrar a sus equipos de desarrollo y colaboradores en su enfoque. Ellos podrán identificar las debilidades y sugerirle soluciones prácticas para optimizar su software de inteligencia artificial.

Casos prácticos y ejemplos reales
Al revolucionar nuestros hábitos de comunicación y trabajo, las herramientas generativas impulsadas por IA se han vuelto rápidamente indispensables. Entre los mejores ejemplos en términos de entrenamiento de modelos, podemos encontrar a OpenAI, que utiliza técnicas avanzadas de Machine Learning y Deep Learning en sus algoritmos.
El aprendizaje del agente conversacional ChatGPT 4, por ejemplo, se basa en el uso de la arquitectura Transformer para analizar datos y generar respuestas relevantes. Luego, OpenAI utiliza técnicas de aprendizaje supervisado y aprendizaje por refuerzo para afinar sus respuestas.
Actualmente, muchas empresas están aprovechando la inteligencia artificial para optimizar sus servicios y automatizar sus procesos. Amazon, por ejemplo, entrena a su asistente de voz Alexa para mejorar la interacción con los usuarios y facilitar la gestión de tareas diarias. Por su parte, los motores de búsqueda como Google y las redes sociales como Facebook perfeccionan sus modelos de IA para identificar las necesidades de los internautas. En España, startups como Sherpa.ai, Braininside y Savana están formando sus modelos para desarrollar aplicaciones que respondan a las necesidades de las empresas.
De hecho, puedes descubrir cómo crear una IA utilizando lenguajes de aprendizaje como Python. Esta herramienta ofrece numerosas bibliotecas y frameworks fáciles de usar. En el caso de la clasificación de imágenes, por ejemplo, solo es necesario proporcionar a Python los datos etiquetados y este se encargará de convertirlos en valores numéricos o píxeles. El algoritmo luego compara sus predicciones y ajusta sus parámetros para reducir errores. A medida que se entrena, tu modelo de IA creado con Python mejorará su capacidad para identificar nuevas imágenes.
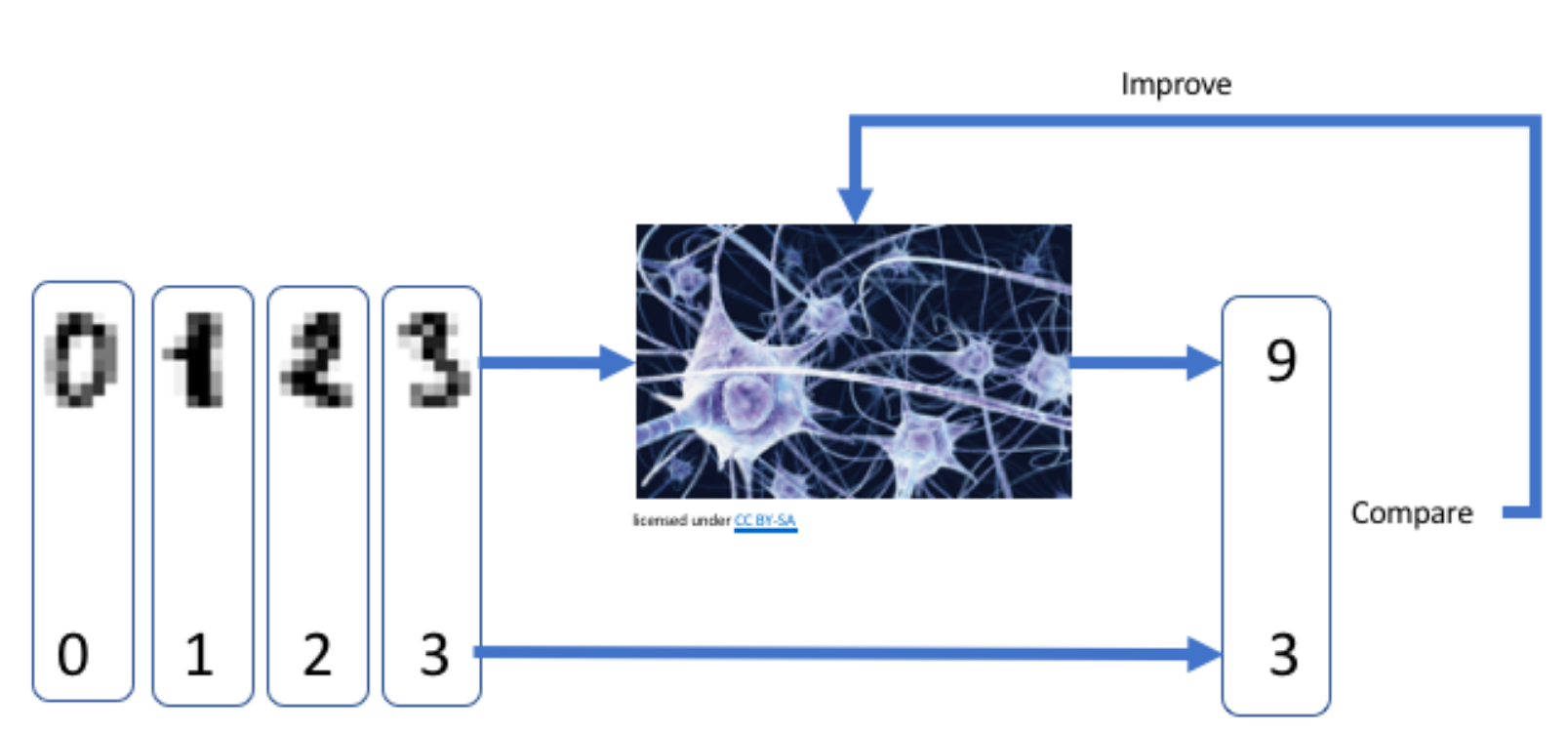
Fuente: culturesciencesphysique.ens-lyon.fr
El Futuro del Entrenamiento de las IA
Automatización del entrenamiento con AutoML
Con el auge de las nuevas tecnologías, el entrenamiento de los modelos de IA se vuelve más eficiente y accesible. Métodos como el aprendizaje automático o AutoML permiten programar gran parte del proceso de entrenamiento, permitiendo que los modelos de IA ajusten sus parámetros sin intervención humana.
Además, las IA autoaprendizaje y las IA que proporcionan fuentes se adaptan continuamente a los nuevos datos, mejorando así su rendimiento en numerosos campos como el comercio y la salud.
Impacto de los modelos de IA de código abierto
Los modelos de código abierto fomentan la innovación gracias a sus numerosas bibliotecas digitales. Además, estos modelos promueven la colaboración entre investigadores y empresas. Con el código abierto, la creación de aplicaciones de IA en Linux, Microsoft Windows, Android e iOS será más accesible.
De hecho, esta evolución se refleja en el uso simultáneo de IA de código abierto y algoritmos internos por parte de plataformas especializadas como Amazon, Coursera, Netflix o Spotify. Estas empresas recurren entonces a los modelos de código abierto para optimizar sus servicios y aplicaciones multimedia.
Evoluciones esperadas en el campo
Gracias a los avances tecnológicos, las empresas podrán mejorar rápidamente la eficiencia y precisión de su modelo de inteligencia artificial. Algunos subcampos como el Deep Learning, por ejemplo, podrán beneficiarse de arquitecturas neuronales más sofisticadas, que harán que la clasificación de imágenes y el reconocimiento de voz sean más eficientes.
En cuanto al procesamiento del lenguaje natural (NLP), el aprendizaje de los algoritmos se basará en los modelos de transformadores. Muchos softwares avanzados como BERT y ChatGPT-4 de OpenAI utilizan actualmente modelos autorregresivos para analizar consultas y generar textos. Estas innovaciones contribuirán al desarrollo de numerosos servicios como la creación de contenido, la atención al cliente y la navegación en los motores de búsqueda.
Conclusión
Desde la recopilación y preparación de los datos, hasta la evaluación del modelo pasando por la elección adecuada de un algoritmo, el entrenamiento de una inteligencia artificial exige rigor y ajustes constantes. Para garantizar un rendimiento óptimo, debes comprender el funcionamiento de los algoritmos y mejorar la precisión de tu modelo mediante un buen análisis.
Si deseas iniciarte en el aprendizaje de una inteligencia artificial, utiliza las plataformas especializadas y experimenta con diferentes enfoques de aprendizaje. Paralelamente, desarrolla tus habilidades y solicita la ayuda de una agencia para optimizar tus modelos. De esta manera, podrás diseñar modelos de IA eficaces adaptados a las necesidades de tu campo.


